The Problem With Plus Signs and S3 Objects
Ever tried downloading files with a plus sign in the filename via S3 object URLs? There’s a catch with those.
S3 Object URLs
You can access public S3 objects via http/s. The url to the objects is typically
https://<bucket-name>.s3.amazonaws.com/<path> where path includes the prefix
directories.
This is very useful and can allow for even hosting an rpm repository. This type of hosting doesn’t provide directory indexing but if you maintain a static index that doesn’t matter.
A problem with this hosting method is when there are plus signs in the path of a file in the bucket. If a file in the bucket is named “hello+world.txt”, you will typically expect the following url to access that file.
https://micho-test-plus-signs.s3.amazonaws.com/hello+world.txt
Surprisingly, instead you’ll receive an access denied error message page.
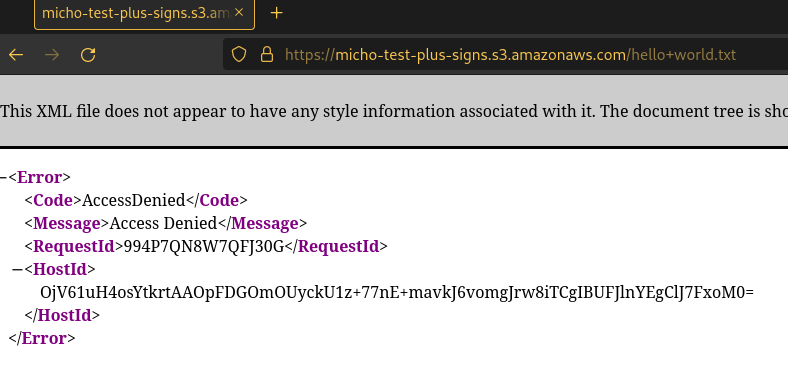
And it’s because of an interesting problem with url encoding spaces.
Spaces, Plus Signs, and URLs
URLs cannot contain spaces. URL encoding normally replaces these with either
plus signs or with %20; and there comes the problem. It’s not possible to
differentiate between a plus symbol or a space when parsing a URL. If a URL
wants to use a plus symbol, it must be explicitly url encoded (replaced with
%2B).
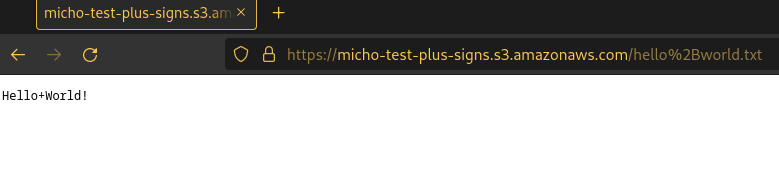
https://micho-test-plus-signs.s3.amazonaws.com/hello%2Bworld.txt
So a workaround for the error shown above when using a plus sign in the URL is
to replace the plus sign with %2B instead (pre-emptive url encoding).
S3 Objects With Spaces
So you might wonder why Amazon does not just by default handle this when doing S3 object access URLs and the reason for that is because of files with a space in their filenames or prefixes.
If a file in a bucket has a space in the filename (which is a valid POSIX filename character) then those can be accessed with URLs where plus symbols replace the spaces.

They can also be accessed by having the spaces url encoded (so replaced with
%20).

So essentially, S3 is doing the right thing with plus symbols and using them to access files in a bucket with spaces in their filename or prefix.
Even if people disagree with this behaviour and think it should work vice-versa
(i.e. plus symbol resolves to plus symbol and spaces need to be url encoded as
%20) changing it now would result in the breaking of backwards compatibility
with S3. If there are two files in a bucket with almost the same filenames (one
has a space and the other has a plus symbol), then changing this behaviour would
change which file is returned via the S3 object URL.
The Issue With RPM Repos
This all seems fine as long as the encoding is explicitly taken care of but one annoying issue stemming from this is when trying to host an RPM repo using S3 object urls. The repo metadata will point dnf/yum to download the files using not-encoded urls. So this breaks dnf when trying to download an RPM like libstdc++.
https://github.com/rpm-software-management/createrepo_c/issues/215 https://github.com/rpm-software-management/librepo/pull/188 https://bugzilla.redhat.com/show_bug.cgi?id=1817130
There’s been discussion in bug tickets and even some PRs to librepo to handle this but still the issue persists in CentOS today. I don’t think url encoding the repo metadata makes sense (this could probably break the repo depending on how it’s hosted).
So I found if you want to host an RPM repo in S3, there’s another way to do that than using S3 object URLs.
Using S3 Websites Instead of S3 Object URLs
There is an alternative to using S3 object URLs to access S3 objects via http. S3 websites can be enabled for buckets to make them accessible and html files can be viewed directly in the browser.
An interesting thing about using this alternative when it comes to the plus
symbol problem is that S3 websites handle them differently than with S3 object
URLs. S3 websites will always interpret plus signs in the URLs as plus signs
and not spaces (i.e. %2B not %20). This means that you can access all objects
via the browser without intervention (as your browser normally encodes spaces
into %20 for you).

I find accessing S3 objects via the S3 website significantly more human friendly.
Summary
So in summary, there are two workarounds to accessing S3 objects with plus symbols in the filename or prefix:
- url encode the plus signs as
%2Bwhen accessing them - use S3 websites instead of S3 object URLs
Comparing S3 Object URLs and S3 Websites
A quick summary of the combinations of spaces, plus symbols and their url encoded counterparts.
In a bucket with two files:
- hello+world.txt
- hello world.txt
We would see the following files returned depending on the URL:
| URL input | S3 Object URL | S3 Website URL |
|---|---|---|
| http://[..]/hello+world.txt | hello world.txt | hello+world.txt |
| http://[..]/hello%2Bworld.txt | hello+world.txt | hello+world.txt |
| http://[..]/hello world.txt | hello world.txt | hello world.txt |
| http://[..]/hello%20world.txt | hello world.txt | hello world.txt |